 Últimamente los conceptos de creacionismo y evolucionismo son objeto de fuertes discusiones filosóficas, políticas y religiosas.
Últimamente los conceptos de creacionismo y evolucionismo son objeto de fuertes discusiones filosóficas, políticas y religiosas.
Y yo aún añadiría un tercer concepto, que es el de la manipulación genética, que ha implicado saltos evolutivos sorprendentes, como en el caso de la aparición del Homo Sapiens. Y casi siempre estos temas se enfocan de una manera radical y condicionada fuertemente por prejuicios morales y religiosos. Sin embargo creemos que estos tres conceptos pueden coexistir y ser perfectamente válidos.
Y esto es lo que intentamos explicar en este artículo. Para ello utilizaré, entre otras, informaciones que nos proporciona la moderna biología molecular. Probablemente algunos de los conceptos que se explicarán resulten algo complicados para muchos lectores, pero son necesarios ya que uno de los objetivos es mostrar que la gran complejidad es incompatible con el azar, lo cual nos lleva a considerar seriamente el concepto del diseño inteligente.

En este punto deseo hacer una aclaración importante, que también he expresado en otros artículos: Lo que parecen indicar las tablillas sumerias, el Génesis (derivado de estas tablillas) y otras evidencias, es que se produjo la creación del Homo Sapiens por parte de unos seres venidos de otro planeta, mediante la manipulación genética, algo que hoy en día ya empezamos a estar en condiciones de hacer y comprender (ver los distintos artículos sobre Sumer). Sin embargo, esto no contradice ni la teoría de la evolución ni la idea de que hay un creador inicial de todo lo existente, a lo que se le suele llamar Dios. Pero parece que los dioses (en realidad no se habla de un único “dios”) bíblico no son este creador inicial, sino “solo” los creadores del Homo Sapiens.
A este respecto deseo hacer referencia a la siguiente frase de D. T. Suzuki, que fue un maestro y divulgador japonés del Budismo, del Zen y del Shin: El significado del Avatamsaka y de su filosofía será incomprensible a menos que experimentemos un estado de completa disolución, donde no exista diferenciación entre la mente y el cuerpo, entre el sujeto y el objeto. Entonces miramos alrededor y vemos eso, que cada objeto está relacionado con todos los demás objetos, no sólo espacialmente, sino temporalmente. Experimentamos que no hay espacio sin tiempo, que no hay tiempo sin espacio; que se interpenetran.” . A lo mejor esto es lo que representa (de una manera parcial, como no podría ser de otra manera) al Todo que llamamos Dios creador.
Por evolución biológica entendemos el conjunto de transformaciones, a través del tiempo, que han originado la diversidad de formas de vida que existen sobre la Tierra, a partir de un supuesto antepasado común. La palabra evolución fue utilizada por vez primera en el siglo XVIII por el suizo Charles Bonnet. Pero el concepto de que la vida en la Tierra evolucionó a partir de un ancestro común ya había sido formulada por diversos filósofos griegos, y la hipótesis de que las especies se transforman continuamente fue postulada por numerosos científicos de los siglos XVIII y XIX, a los que Charles Darwin citó en su libro “El origen de las especies”. Dos naturalistas, Charles Darwin y Alfred Russel Wallace propusieron en 1858, en forma independiente, que la selección natural es el mecanismo básico responsable del origen de nuevas variantes fenotípicas, en que se incluyen rasgos tanto físicos como conductuales, así como de nuevas especies. Actualmente, la teoría de la evolución combina las propuestas de Darwin y Wallace con las leyes de la herencia de Mendel y con otros avances de la genética.
Actualmente los investigadores del origen de la vida consideran que el problema del origen de la información biológica(básicamente el ADN, el ARN y las proteínas) es el problema central al que se enfrentan. Sin embargo, el término “información” puede referirse a varios conceptos distintos. El objetivo es evaluar distintas explicaciones sobre el origen de la información biológica, especialmente la adecuación de las explicaciones de la química naturalista evolutiva en relación al origen de la información biológica específica, tanto si se basan en el “azar” o en la “necesidad”, o en ambos. Y el actual estado de conocimiento apunta al diseño inteligente como mejor explicación y más adecuada con respecto al origen de la información biológica específica. Las categorías de “azar” y “necesidad” son útiles para comprender la historia reciente de la investigación del origen de la vida. Hasta mediados del siglo XX, los investigadores se apoyaron principalmente en teorías que se centraban en el papel creativo de los eventos aleatorios, el “azar”, vinculados con ciertas formas de selección natural. Y posteriormente los teóricos se han centrado en las leyes o propiedades deterministas de la autoorganización o de la “necesidad” físico-química.
Las teorías sobre el origen de la vida implican el conocimiento de los atributos de las células vivas. Según el historiador de la biología Harmke Kamminga, “en el corazón del problema del origen de la vida hay una cuestión fundamental: ¿De qué, exactamente, estamos intentado explicar el origen?”. O, como afirma el pionero de la química evolutiva Alexander Oparin, “el problema de la naturaleza de la vida y el problema de su origen se han vuelto inseparables”. Y los biólogos moleculares se refieren al ADN, al ARN y a las proteínas como los auténticos portadores de esta “información”. Como ha dicho Bernd Olaf Kuppers, profesor de filosofía de la naturaleza: “claramente, el problema del origen de la vida equivale básicamente al problema del origen de la información biológica”.
La única opinión conocida de Darwin sobre el origen de la vida se encuentra en una carta dirigida a Joseph Hooker, botánico británico. En ella, dibuja las líneas maestras de la química evolutiva, a saber, que la vida podría haber surgido primero a partir de una serie de reacciones químicas. Tal y como él escribió, “si pudiéramos creer en algún tipo de pequeño charco caliente, con toda clase de amonios, sales fosfóricas, luz, calor y electricidad, etc, presentes, de modo que un compuesto proteico se formara químicamente listo para someterse a cambios aún más complejos…”. El resto de la frase es ilegible, si bien deja bastante claro que Darwin concibió los principios de la química evolutiva naturalista.
Después de que Darwin publicara su obra maestra “El Origen de las Especies”, muchos científicos comenzaron a pensar en los problemas que Darwin todavía no había resuelto. Aunque la teoría de Darwin pretendía explicar cómo se había hecho más compleja la vida a partir de “una o unas pocas formas simples”, no explicaba ni tampoco intentaba explicar como se había originado la vida. Sin embargo, a finales del siglo XIX, algunos biólogos evolutivos como Ernst Haeckel y Thomas Huxley suponían que encontrar una explicación para el origen de la vida sería bastante fácil, en gran parte porque Haeckel y Huxley creían que la vida era, en esencia, una sustancia química simple llamada “protoplasma” que podía ser fácilmente elaborada mediante la combinación y recombinación de reactivos simples como el dióxido de carbono, el oxígeno y el nitrógeno.
Durante los siguientes años, los biólogos y los bioquímicos revisaron su concepción de la naturaleza de la vida. Durante el siglo XIX los biólogos, como Haeckel, vieron la célula como un glóbulo de plasma homogéneo e indiferenciado. Sin embargo, ya en el el siglo XX, la mayoría de los biólogos veían las células como un sistema metabólico complejo. Las teorías del origen de la vida reflejaron esta creciente visión de la complejidad celular. Mientras que las teorías decimonónicas concebían la vida como algo surgido casi instantáneamente a través de uno o dos pasos de un proceso de “autogenia” química, las teorías de comienzos del siglo XX concebían un proceso de varios billones de años de transformación desde los reactivos simples hasta los sistemas metabólicos complejos.
.
Durante la primera mitad del siglo XX, los bioquímicos habían reconocido el papel central de las proteínas en el mantenimiento de la vida. Aunque muchos creyeron erróneamente que las proteínas contenían también la información hereditaria, los biólogos subestimaron la complejidad de las proteínas. Sin embargo, a partir de mediados del siglo XX, una serie de descubrimientos provocó un cambio en esta visión simplista de las proteínas. El bioquímico Fred Sanger determinó la estructura molecular de la insulina y demostró que consistía en una secuencia larga e irregular de los diferentes tipos de aminoácidos. Su trabajo mostró para una sola proteína lo que sucesivos trabajos demostrarían que era la norma: la secuencia de aminoácidos de las proteínas funcionales se caracteriza por su complejidad. Los trabajos del químico inglés John Kendrew sobre la estructura de la mioglobina demostraron que las proteínas también mostraban una sorprendentecomplejidad tridimensional. Lejos de ser las estructuras simples que los biólogos habían imaginado anteriormente, apareció una forma tridimensional e irregular extraordinariamente compleja. E incluso actualmente se especula con que en realidad se trata de una estructura multidimensional, con varias dimensiones no “observables”.
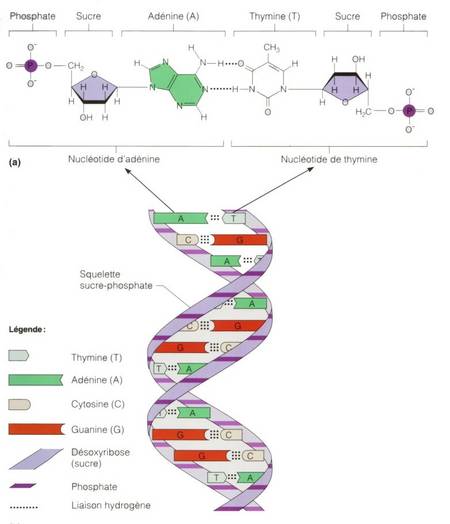
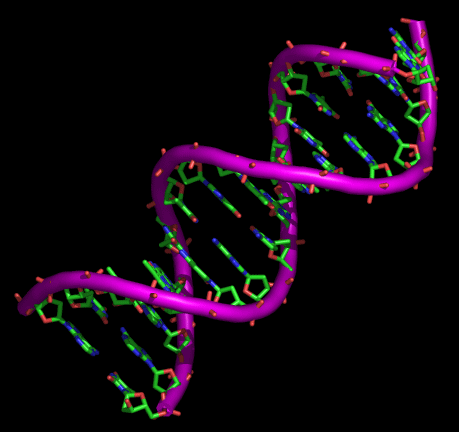
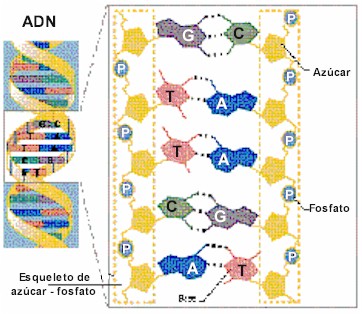
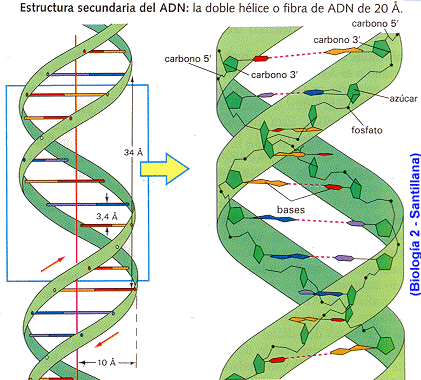
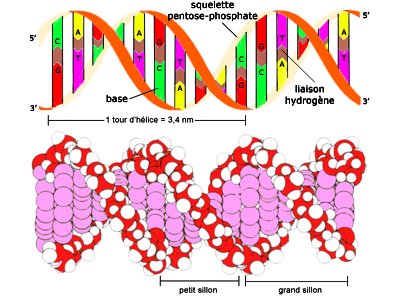
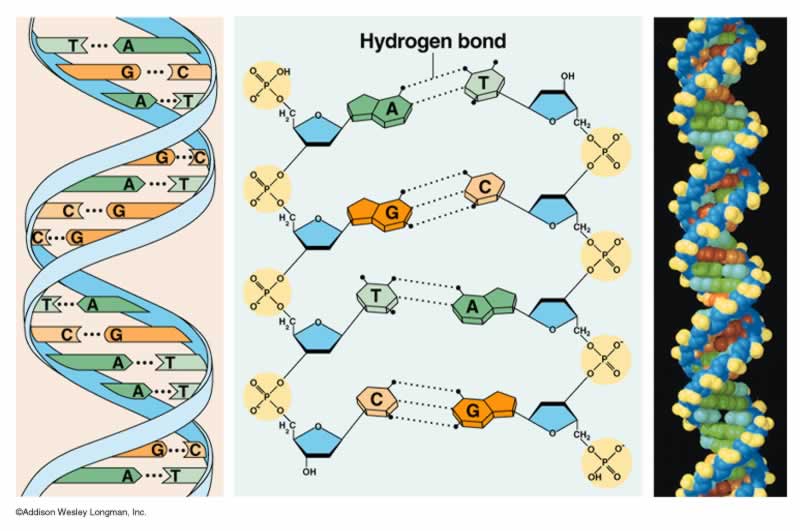
Durante gran parte del siglo XX, los investigadores subestimaron ampliamente la complejidad y el significado de ácidos nucleicos como el ADN o el ARN. Por entonces, los científicos conocían la composición química del ADN. Los biólogos y los químicos sabían que además de azúcar y fosfatos, el ADN se componía de cuatro bases diferentes, llamadas adenina, timina, guanina y citosina. El descubrimiento de la estructura tridimensional del ADN por Watson y Crick en 1953 dejó claro que el ADN podía funcionar como portador de la información hereditaria. El modelo propuesto por Watson y Crick concebía una estructura de doble hélice para explicar la forma de cruz de Malta de los patrones obtenidos por los estudios del ADN realizados por Franklin, Wilkins y Bragg a comienzos de los años 50 mediante cristalografía de rayos X. Tal y como explicaron Watson y Crick, “el esqueleto de azúcar-fosfato de nuestro modelo es completamente regular pero cualquier secuencia de pares de bases puede encajar en nuestra estructuras. De aquí se sigue que en una larga molécula son posibles muchas permutaciones diferentes y, por lo tanto, parece posible que la secuencia precisa de bases sea el código portador de la información genética”.
Tal y como sucedió con las proteínas, los sucesivos descubrimientos pronto demostraron que las secuencias de ADN no solo eran muy complejas sino también altamente específicas en lo relativo a sus requerimientos biológico-funcionales. El descubrimiento de la complejidad y la especificidad de las proteínas habían llevado a los investigadores a sospechar un papel funcional específico para el ADN. Los biólogos moleculares se iban percatando de que las proteínas eran demasiado complejas y específicas para surgir por azar. Además, dada su irregularidad, parecía imposible que una ley química general o una regularidad pudiese explicar su ensamblaje. En su lugar, como ha recordado Jacques Monod, los biólogos moleculares comenzaron a buscar una fuente de información o de “especificidad” en el interior de la célula que pudiera dirigir la construcción de estructuras tan complejas y tan altamente específicas. Para explicar la presencia de la especificidad y complejidad en la proteína, tal y como más tarde insistiría Monod, “necesitabais en todo caso un código”.
La estructura del ADN descubierta por Watson y Crick sugería un medio por el que la información o la especificidad podían codificarse a lo largo de la espiral del esqueleto de azúcar-fosfato. Según la hipótesis de secuencia de Crick, la especificidad en el ordenamiento de los aminoácidos en la proteína deriva de la especificidad en el ordenamiento de las bases nucleotídicas en la molécula de ADN. La hipótesis de secuencia sugería que las bases nucleotídicas en el ADN funcionaban como letras de un alfabeto o caracteres en una máquina de codificar. Del mismo modo como las letras de un alfabeto en un lenguaje escrito pueden realizar la función de comunicación dependiendo de su secuencia, igualmente podrían las bases nucleotídicas del ADN originar la producción de una molécula funcional de proteína dependiendo de su preciso ordenamiento secuencial. En ambos casos, la función depende de manera crucial de la secuencia. La hipótesis de secuencia implicaba no solo la complejidad sino también la funcionalidad específica de las bases de la secuencia de ADN.
La ausencia de predecibilidad hace que el concepto de información sea teóricamente superfluo para la biología molecular. En cambio, lo impredecible muestra que la especificidad de secuencia de las bases del ADN constituye condición necesaria, pero no suficiente, para lograr el plegamiento proteico, es decir, el ADN contiene información específica, pero no la suficiente para determinar por sí misma el plegamiento de la proteína.
La presencia de un sistema de procesamiento de la información, complejo y funcionalmente integrado, sugiere efectivamenteque la información de la molécula de ADN es insuficiente para producir la proteína. Ello no demuestra que tal información sea innecesariapara producir las proteínas, ni invalida la afirmación de que el ADN almacena y transmite información genética específica.
Desde el comienzo de la revolución de la biología molecular, los biólogos asignaron al ADN, al ARN y a las proteínas lapropiedad de transportar información. En la jerga de la biología molecular, la secuencia de bases del ADN contiene la “información genética” o las “instrucciones de ensamblaje” necesarias para dirigir la síntesis de proteínas. Sin embargo, el término información puede denotar varios conceptos teóricamente diferentes. Así, se puede preguntar en qué sentido se aplica “información” a estas grandes macromoléculas. Veremos que los biólogos moleculares emplean tanto un concepto de la información más fuerte que el que emplean los matemáticos y los teóricos de la información y una concepción del término ligeramente más débil que el que emplean los lingüistas y los usuarios ordinarios.
La teoría de la información de Shannon ayudó a refinar la comprensión biológica de una característica importante de los componentes biomoleculares cruciales de los que depende la vida: el ADN y las proteínas son altamente complejas y cuantificables. La teoría de la información ayudó a establecer que el ADN y las proteínas podían llevar grandes cantidades de información funcional; no a establecer si realmente lo hacían. Los biólogos moleculares como Monod y Crick entendían la información, almacenada en el ADN y las proteínas, como algo más que la mera complejidad o improbabilidad. En realidad, su idea de información asociaba con las secuencias de ADN tanto la contingencia bioquímica como la complejidad combinatoria. Los avances de la teoría de la complejidad han hecho posible una explicación general plenamente teórica de la especificación, que se aplica fácilmente a los sistemas biológicos.
Las regiones codificantes del ADN funcionan de manera muy parecida a un programa de software o al código de una máquina, dirigiendo operaciones dentro de un sistema material complejo a través de secuencias de caracteres altamente complejas y sin embargo específicas. Como ha señalado Richard Dawkins “el código de máquina de los genes es increíblemente parecido al de una computadora”. O como ha notado Bill Gates, “el ADN es como un programa de computadora pero mucho, mucho más avanzado que ninguno que hayamos creado”. Del mismo modo que con el ordenamiento específico de dos símbolos (0 y 1) en un programa de ordenador se puede realizar una función en un entorno de máquina, también la secuencia precisa de las cuatro bases del ADN pueden realizar una función dentro de la célula.
Como sucede en el código de máquina de una computadora, la especificidad de secuencia del ADN sucede dentro de un dominio sintáctico. Así, el ADN contiene información tanto sintáctica como específica. En cualquier caso, desde los últimos años, el concepto de información, tal y como lo emplean los biólogos moleculares, ha fusionado las nociones de complejidad o improbabilidad y especificidad de función. Los constituyentes biomoleculares cruciales de los organismos vivos contienen no solo información sintáctica sino también “información específica”. Por tanto, la información biológica así definida constituye una característica principal de los sistemas vivos cuyo origen debe explicar cualquier modelo acerca del origen de la vida. Los descubrimientos de los biólogos moleculares suscitaron la pregunta por el origen último de la complejidad específica o información específica tanto en el ADN como en las proteínas. Por lo menos desde mediados de los años 60, muchos científicos han considerado el origen de la información como la cuestión central con que se enfrentaba la biología del origen de la vida. Según esto, los investigadores del origen de la vida han propuesto tres grandes tipos de explicaciones naturalistas para explicar el origen de la información genética específica; los que hacen hincapié en el azar, en la necesidad o en la combinación de ambos.
Quizás el punto de vista naturalista más popular acerca del origen de la vida es que éste tuvo lugar exclusivamente por azar. Pero solo unos pocos científicos serios han manifestado su apoyo a este punto de vista. Casi todos los investigadores serios del origen de la vida consideran ahora el “azar” una explicación causal inadecuada para el origen de la información biológica. Desde que los biólogos moleculares comenzaron a apreciar la especificidad de secuencia de proteínas y ácidos nucleicos, se han realizado muchos cálculos para determinar la probabilidad de formular proteínas y ácidos nucleicos funcionales. Tales cálculos han mostrado invariablemente que la probabilidad de obtener biomacromoléculas secuenciadas funcionales al azar es “infinitamente pequeña… incluso en la escala de… billones de años”.
Deben tenerse en cuenta las dificultades probabilísticas que deben superarse para construir incluso una proteína corta de 100 aminoácidos de longitud. (Una proteína típica consiste en unos 300 y muchas proteínas importantes son más largas). Todos los aminoácidos deben formar un enlace químico conocido como enlace peptídico al unirse a otros aminoácidos de la cadena proteica. Sin embargo, en la naturaleza son posibles otros muchos tipos de enlace químico entre aminoácidos. Así, dado un sitio cualquiera de la cadena de aminoácidos en crecimiento, la probabilidad de obtener un enlace peptídico es aproximadamente ½. La probabilidad de obtener cuatro enlaces peptídicos es (½ x ½ x ½ x ½) = 1/16. La probabilidad de construir una cadena de 100 aminoácidos en la cual todos los enlaces impliquen enlaces es de aproximadamente 1 en 1030.
Pero todos los aminoácidos que se encuentran en las proteínas tienen una imagen especular diferente de sí mismos, una versión orientada a la izquierda y una orientada a la derecha. Las proteínas funcionales solo admiten aminoácidos orientados a la izquierda. Sin embargo tanto los orientados a la derecha como los orientados a la izquierda se originan en las reacciones químicas productoras de aminoácidos con aproximadamente la misma probabilidad. Esto aumenta la improbabilidad de obtener una proteína biológicamente funcional.
La probabilidad de obtener al azar solo aminoácidos orientados a la izquierda en una cadena peptídica hipotética de 100 aminoácidos de longitud es de aproximadamente 1 en 1030. Partiendo de mezclas de formas a la derecha y a la izquierda, la probabilidad de construir al azar una cadena de 100 aminoácidos de longitud en la que todos los enlaces sean enlaces peptídicos y todos los aminoácidos sean formas a la izquierda es de 1 en 1060.
Pero las proteínas funcionales tienen un tercer requisito independiente, el más importante de todos; sus aminoácidos deben enlazarse en un ordenamiento específico secuencial, tal y como deben hacerlo las letras en una frase con significado. En algunos casos, incluso el cambio de un aminoácido en un determinado lugar provoca la pérdida de funcionalidad en la proteína. Además, debido a que biológicamente se dan veinte aminoácidos, la probabilidad de obtener un determinado aminoácido en un sitio determinado es pequeña: 1/20. Y la probabilidad de lograr todas las condiciones de función necesarias para una proteína de 150 aminoácidos de longitud excede de 1 en 10180. Como ha dicho el divulgador científico Richard Dawkins, “podemos aceptar cierta cantidad de suerte en nuestras explicaciones pero no demasiada”. Lógicamente, la afirmación de Dawkins da por sentada una cuestión cuantitativa, a saber, “¿cómo de improbable tiene que ser un suceso, una secuencia o un sistema para que la hipótesis del azar pueda ser razonablemente eliminada?”.
El matemático estadounidense William Albert Dembski calcula una estimación conservadora del “límite de probabilidad universal” en 1 en 10150, que corresponde a los recursos probabilísticos del universo conocido. Este número proporciona la base teórica para excluir las apelaciones al azar como la mejor explicación de sucesos específicos de probabilidad menores. Dembski contesta la pregunta de cuanta suerte, para un caso determinado, puede invocarse como explicación. De manera significativa, la improbabilidad de construir y secuenciar incluso una proteína funcional corta se acerca a este límite de probabilidad universal, que esel punto en el que las apelaciones al azar se convierten en absurdas dados los “recursos probabilísticos” de todo el universo. Además, haciendo el mismo tipo de cálculo para proteínas moderadamente largas lleva estas mediciones bastante más allá del límite.
Así, supuesta la complejidad de las proteínas, es extremadamente imposible que una búsqueda aleatoria en el espacio de secuencias de aminoácidos posibles, desde el punto de vista combinatorio, pudiera generar incluso una proteína funcional relativamente corta en el tiempo disponible desde el comienzo del universo (y menos desde el origen de la Tierra). Por el contrario, para tener una posibilidad razonable de encontrar una proteína funcional corta en una búsqueda al azar del espacio combinatorio requeriría enormemente más tiempo del que permiten la geología o la cosmología.
Cálculos más realistas solo aumentan estas improbabilidades, incluso más allá de lo computable. Por ejemplo, recientes trabajos experimentales y teóricos sobre la denominada complejidad mínima requerida para mantener el organismo viviente más simple posible sugieren un límite inferior de entre 250 y 400 genes y sus correspondientes proteínas. El espacio de secuencias de nucleótidos correspondiente a este sistema de proteínas excede de 4 300.000. La improbabilidad que corresponde a esta medida de complejidad molecular de nuevo excede enormemente de los “recursos probabilísticos” de todo el universo. Cuando se considera todo el complemento de biomoléculas funcionales requerida para mantener la mínima función celular y la vitalidad, puede verse las razones por las que las teorías sobre el origen de la vida basadas en el azar han sido abandonadas por los ciéntificos.
Christian de Duve y otros investigadores han reconocido hace tiempo que la célula representa no solo un sistema altamente improbable sino también un sistema funcionalmente específico. Por esta razón, a mediados de los años 60, la mayoría de los investigadores habían eliminado el azar como explicación plausible del origen de la información específica necesaria para construir una célula. En cambio muchos han buscado otros tipos de explicación naturalista. A mediados del siglo XX, John von Neumann demostró que todo sistema capaz de autorreplicarse requeriría subsistemas que fueran funcionalmente equivalentes a los sistemas de almacenamiento, reinformación, replicación y procesado de las células existentes. Sus cálculos establecieron un umbral mínimo muy alto para la función biológica, del mismo modo que haría más tarde en un trabajo experimental. Estos requerimientos de complejidad mínima plantean una dificultad fundamental para la selección natural. La selección natural selecciona ventajas funcionales. Por tanto, no puede jugar ningún papel hasta que las variaciones aleatorias produzcan algún ordenamiento biológicamente ventajoso de importancia.
 Sin embargo, los cálculos de John von Neumann y otros similares de Wigner, Landsberg y Morowitz demostraron que con toda probabilidad las fluctuaciones aleatorias de moléculas no producirían la complejidad mínima necesaria para un sistema de replicación primitivo. La improbabilidad de desarrollar un sistema de replicación funcionalmente integrado excede enormemente la de desarrollar los componentes proteicos o de ADN de estos sistemas. Dada la gigantesca improbabilidad y el elevado umbral funcional que implica, muchos investigadores de origen de la vida han acabado considerando la selección natural prebiótica inadecuada y esencialmente indistinguible de las invocaciones al azar.
Sin embargo, los cálculos de John von Neumann y otros similares de Wigner, Landsberg y Morowitz demostraron que con toda probabilidad las fluctuaciones aleatorias de moléculas no producirían la complejidad mínima necesaria para un sistema de replicación primitivo. La improbabilidad de desarrollar un sistema de replicación funcionalmente integrado excede enormemente la de desarrollar los componentes proteicos o de ADN de estos sistemas. Dada la gigantesca improbabilidad y el elevado umbral funcional que implica, muchos investigadores de origen de la vida han acabado considerando la selección natural prebiótica inadecuada y esencialmente indistinguible de las invocaciones al azar.
Para muchos científicos los modelos autoorganizativos parecen representar ahora el enfoque más prometedor para explicar el origen de la información biológica específica. Se sabe que la estructura del ADN depende de varios enlaces químicos. Por ejemplo, hay enlaces entre el azúcar y las moléculas de fosfato que forman los dos esqueletos contorsionados de la molécula de ADN. Hay enlaces que fijan las bases (los nucleótidos) al esqueleto de azúcar-fosfato a cada lado de la molécula. Hay también enlaces de hidrógeno horizontales a lo largo de la molécula entre las bases de nucleótidos, originando así las denominadas bases complementarias. Los enlaces de hidrógeno individualmente débiles, que en su conjunto mantienen juntas las dos copias complementarias de ADN, hacen posible la replicación de las instrucciones genéticas. Sin embargo, es importante notar que no hay enlaces químicos entre las bases a lo largo del eje longitudinal en el centro de la hélice.
Sin embargo, es precisamente a lo largo de este eje de la molécula de ADN donde se almacena la información genética. Además, del mismo modo que letras magnéticas pueden ordenarse y reordenarse de cualquier manera sobre la superficie de un metal para formar varias secuencias, así también cada una de las cuatro bases –A, T, G y C- se unen a cualquier posición del esqueleto de ADN con igual facilidad, haciendo todas las secuencias igualmente probables (o improbables). Por lo indicado, las afinidades de enlace “autoorganizativas” no pueden explicar los ordenamientos secuencialmente específicos de las bases de nucleótidos del ADN, porque no hay enlaces entre las bases a lo largo del eje molecular que contiene la información y no hay afinidades diferenciales entre el esqueleto y las bases específicas que pudieran explicar las variaciones de secuencia. Debido a que esto mismo es válido para las moléculas de ARN, los investigadores que especulan que la vida comenzó en un mundo de ARN no han podido resolver el problema de como la información de las moléculas funcionales de ARN pudo surgir por vez primera.
Para los que quieren explicar el origen de la vida como resultado de propiedades de autoorganización intrínsecas de los materiales que constituyen los sistemas vivientes, estos hechos bastante elementales de la biología molecular tienen implicaciones decisivas. El lugar más obvio para buscar propiedades de autoorganización para explicar el origen de la información genética son las partes constituyentes de las moléculas que llevan la información. Pero la bioquímica y la biología molecular dejan claro que las fuerzas de atracción entre los componentes de ADN, ARN y proteínas no explican la especificidad de secuencia de estas grandes moléculas transportadoras de información.
Como ha dicho de Christian de Duve: “los procesos que generaron la vida fueron altamente deterministas, haciendo inevitable la vida tal y como la conocemos dadas las condiciones que existieron en la tierra prebiótica”. Sin embargo, imagínense las condiciones prebióticas más favorables. Imagínese un charco con las cuatro bases del ADN y todos los azúcares y fosfatos necesarios; ¿surgiría cualquier secuencia genética de manera inevitable?, ¿surgiría inevitablemente cualquier proteína o gen funcional, no digamos ya un código genético específico o sistema de replicación?Evidentemente no.
Si los intentos de resolver el problema de la información no lo resuelven ni el azar ni la necesidad físico-química, ni la combinación de los dos, ¿Cuál es la explicación? Según la experiencia puede decirse que: “para todos los sistemas no biológicos, las grandes cantidades de complejidad o información específicas se originan tan solo a partir de una acción mental, una actividad consciente o de diseño inteligente”. Los científicos Meyer, Ross, Nelson y Chien, en la obra “La explosión cámbrica: el “Big Bang” de la biología” aducen que ni el mecanismo neo-darwiniano ni ningún otro mecanismo naturalista explica adecuadamente el origen de la información requerida para construir las nuevas proteínas y diseños corporales que aparecen en la explosión cámbrica. En todo caso, la generalización empírica más exitosa es suficiente para apoyar el argumento de que el diseño inteligente es la mejor explicación del origen de la información específica necesaria para el origen de la vida primigenia.
La experiencia afirma que la complejidad específica o información surge de manera rutinaria de la actividad de agentes inteligentes. Un usuario de ordenadores que rastrea la información en su pantalla hasta su fuente, se introduce en la mente del ingeniero de software o programador. De manera similar, la información en un libro o en la columna de un periódico deriva en última instancia de un escritor, o sea de una causa mental antes que estrictamente material. Además, el conocimiento existente acerca del flujo de información, basado en la experiencia, confirma que los sistemas con grandes cantidades de complejidad o información, tales como los códigos y el lenguaje, invariablemente se originan a partir de una fuerza inteligente, es decir, de la mente de un agente personal. Además, esta generalización se mantiene no solo para la información semánticamente especificada presente en los lenguajes naturales, sino también para otras formas de información o complejidad especificada tanto la presente en los códigos de máquina, como en las máquinas o en las obras de arte.
Al igual que letras en la sección de un texto con significado, las partes de un motor funcional representan una configuración altamente improbable aunque funcionalmente especificada. De igual manera, las formas de los presidentes de los EUA, altamente improbables, de las rocas del Monte Rushmore se conforman a un patrón independientemente dado: los rostros de los presidentes de América conocidos por los libros y las pinturas. Así, ambos sistemas tienen una gran cantidad de complejidad especificada o información así definida. No es una coincidencia que se originaran por un diseño inteligente y no por azar y/o necesidad físico química.
Está claro que la expresión “grandes cantidades de información específica” da por sentado nuevamente otra cuestión cuantitativa, a saber, “¿cuanta complejidad o información específica tendría que tener una célula mínimamente compleja para que ello implicara diseño?”. Antes hemos indicado que Dembski calculó un valor umbral de probabilidad universal de 1/10150, que corresponde a los recursos de probabilidad y de especificidad del universo conocido.
El valor umbral de probabilidad universal se traduce aproximadamente en 500 bits de información. Por lo tanto, el azar solamente no constituye explicación suficiente para el origen de cualquier secuencia o sistema específicos que contenga más de 500 bits de información.
Además, dado que los sistemas caracterizados por la complejidad desafían ser explicados mediante leyes autoorganizativas, Y dado que las invocaciones a la selección natural prebiótica presuponen pero no explican el origen de la información específica necesaria para un sistema autorreplicativo medianamente complejo, el diseño inteligente es la mejor explicación del origen de los más de 500 bits de información específica requerida para producir el primer sistema vivo mínimamente complejo. Así, suponiendo un punto de partida no biológico, la aparición de 500 bits o más de información específica indican diseño de manera fiable.
La generalización de que la inteligencia es la única causa de información o complejidad especificada, por lo menos, a partir de una fuente no biológica, ha obtenido el apoyo de la investigación sobre el origen de la vida. Durante los últimos cuarenta años, todo modelo naturalista propuesto ha fracasado a la hora de explicar el origen de la información genética específica requerida para construir una célula viviente. Así, mente o inteligencia, o lo que los filósofos llaman “agente causal”, es ahora la única causa conocida capaz de generar grandes cantidades de información a partir de un estado abiótico. Como resultado, la presencia de secuencia específicas ricas en información incluso en los más simples sistemas vivientes implicaría un diseño inteligente.
Recientemente ha sido desarrollado un modelo teórico formal de deducción del diseño para apoyar esta conclusión. En su libro “La inferencia de diseño”, el matemático y probabilista teórico William Dembski señala que los agentes racionales a menudo infieren o detectan la actividad a priori de otras mentes por el tipo de efectos que dejan tras ellos. Por ejemplo, los arqueólogos suponen que agentes racionales produjeron las inscripciones en la piedra de Rosetta; los investigadores de fraude de seguros detectan ciertos “patrones de estafa” que sugieren la manipulación intencional de las circunstancias; los criptógrafos distinguen entre signos aleatorios y aquellos que llevan codificados los mensajes. El trabajo de Dembski muestra que reconocer la actividad de agentes inteligentes constituye un modo común, totalmente racional, de inferencia.
Y lo que es más importante, Dembski identifica los criterios que permiten a los observadores humanos reconocer actividad inteligente y distinguir los efectos de tal actividad respecto de los efectos de causas estrictamente materiales. Señala que invariablemente atribuimos a causas inteligentes, diseño-, y no al azar o a leyes físico-químicas,sistemas, secuencias o sucesos que tienen las propiedades conjuntas de “alta complejidad” (o baja probabilidad) y “especificidad”.
Estos patrones de inferencia reflejan nuestro conocimiento de la manera en que el mundo funciona. Por ejemplo, dado que la experiencia enseña que los sucesos o sistemas complejos y específicos surgen invariablemente de causas inteligentes, podemos inferir diseño inteligente de sucesos que muestran conjuntamente las propiedades de complejidad y especificidad. El trabajo de Dembski sugiere un proceso de evaluación comparativa para decidir entre causas naturales e inteligentes basado en las características de probabilidad o “firmas” que dejan tras ellas.
De esta manera vemos que la teoría de Dembski, cuando se aplica a la biología molecular, implica que el diseño inteligente jugó un papel en el origen de la información biológica. El cálculo lógico sigue un método que se usa en las ciencias forenses e históricas. En las ciencias de la historia, el conocimiento de las inferencias actuales, potencias causales de varias entidades y procesos permite a los científicos hacer inferencias acerca de las causas posibles en el pasado. Cuando un estudio minucioso de varias causas posibles produce solo una sola causa adecuada para un efecto dado, los científicos forenses o históricos pueden hacer inferencias definitivas acerca del pasado. Efectivamente, ya que la experiencia afirma que la mente o el diseño inteligente son condición y causa necesaria de la información, puede detectarse la acción pasada de una inteligencia a partir de un efecto rico en información, incluso si la causa misma no puede ser directamente observada.
El ordenamiento específico y complejo de las secuencia nucleotídicas del ADN implica la acción pasada de una inteligencia, incluso si tal actividad mental no puede ser directamente observada. Muchos admiten que podemos inferir con justificación la acción de una inteligencia operativa en el pasado, dentro del ámbito de la historia humana, a partir de un artefacto o un suceso rico en información, pero solamente porque ya sabemos que existe la mente humana. Pero aducen que inferir la acción de un agente diseñador que antecede a los humanos no puede justificarse, incluso cuando observamos un efecto rico en información, dado que no sabemos si un agente o agentes inteligentes existieron con anterioridad a los humanos.

Sin embargo los científicos del SETI tampoco saben si existe o no una inteligencia extraterrestre. Pero suponen que la presencia de una gran cantidad de información específica, como la secuencia de los 100 primeros números primos, establecería definitivamente su existencia. Efectivamente, SETI busca precisamente establecer la existencia de otras inteligencias en un dominio desconocido. De manera similar, los antropólogos han revisado a menudo sus estimaciones sobre el comienzo de la historia humana o de la civilización porque han descubierto artefactos ricos en información procedentes de épocas que anteceden a sus estimaciones previas. Y, tal como hemos explicado en varios artículos, la presencia extraterrestre en distintas épocas de la historia es bastante evidente.
La mayoría de las inferencias de diseño establecen la existencia o la actividad de un agente mental operativo (al que generalmente llamamos Dios) en un tiempo o lugar en el que la presencia de tal agente era previamente desconocido. Por tanto, inferir la actividad de una inteligencia diseñadora en un tiempo anterior al advenimiento de los humanos en la Tierra no tiene un estatus cualitativamente distinto de otras inferencias de diseño que ya se aceptan como reales y producidas por causas naturales; la búsqueda de inteligencia artificial extraterrestre de la NASA (SETI) presupone que cualquier información incluida en las señales electromagnéticas proveniente del espacio exterior indicaría una fuente inteligente. Sin embargo, de momento, los radioastrónomos no han encontrado ninguna información en las señales. Pero los biólogos moleculares han identificado las secuencias ricas en información y los sistemas de las células que sugieren, por la misma lógica, una causa inteligente para esos efectos.
Algunos opinan que cualquier argumento sobre el diseño inteligente constituye un argumento desde la ignorancia o el fanatismo religioso. Los objetores acusan a los defensores del diseño de utilizar nuestra ignorancia presente acerca de cualquier causa de información, natural y suficiente, como base única para inferir una causa inteligente de la información presente en la célula. Dado que aún no sabemos como pudo surgir la información biológica, invocamos la noción misteriosa de diseño inteligente. Según este punto de vista, el diseño inteligente funciona no como explicación sino como un sustituto de la ignorancia.
Aunque la inferencia de diseño a partir de la presencia de información en el ADN no significa tener una prueba de certeza deductiva del diseño inteligente, no constituye un argumento surgido de la ignorancia. Los argumentos nacidos de la ignorancia se dan cuando la evidencia en contra de la proposición X es presentada como la única razón para aceptar una proposición Y alternativa. En todo caso, la supuesta ignorancia acerca de cualquier causa natural suficiente es solo parte de la base para inferir diseño. También se sabeque los agentes inteligentes pueden y de hecho producen sistemas ricos en información: tenemos un conocimiento positivo basado en la experiencia de una causa alternativa que es suficiente, a saber, la inteligencia. Por esta razón, la inferencia de diseño no constituye un argumento de ignorancia sino una inferencia para la mejor explicación.
Consideramos que el argumento del diseño inteligente es la mejor explicación del origen de la información biológica. Como hemos visto, ningún escenario basado en el azar, en la necesidad, o en una combinación de ambos, puede explicar el origen de la información biológica específica en un contexto prebiótico. Este resultado concuerda con la experiencia: Los procesos naturales no producen estructuras ricas en información a partir puramente de precursores físicos o químicos. Tampoco la materia, tanto si actúa al azar como bajo la fuerza de la necesidad físico-química, se ordena a si misma en secuencias complejas ricas en información.

Sin embargo, no es correcto decir que no sabemos como surge la información. Sabemos por experiencia que los agentes conscientes inteligentes pueden crear secuencias y sistemas informativos. La creación de nueva información está asociada habitualmente con la actividad consciente. Además, la experiencia enseña que cuando grandes cantidades de información o complejidad especificada están presentes en un artefacto o entidad cuya historia es conocida, invariablemente la inteligencia creativa, o el diseño inteligente, ha jugado un papel causal en el origen de esa entidad. Así, cuando encontramos tal información en las biomacromoléculas necesarias para la vida, podemos inferir, basándonos en el conocimiento de las relaciones de causa y efecto, que una causa inteligente operó en el pasado para producir la información o complejidad especificada necesaria para el origen de la vida.
Esta inferencia de diseño emplea el mismo método de argumentación y razonamiento que los científicos de la historia utilizan generalmente. En el “Origen de las especies”, Darwin desarrolla su argumento a favor de un ancestro común universal como inferencia para la mejor explicación. Como explicó en una carta a Asa Gray: “Compruebo esta hipótesis [de ascendencia común] comparando con tantas proposiciones generales y muy bien establecidas como puedo encontrar –en distribuciones geográficas, historia geológica, afinidades, etc. Y me parece que, suponiendo que tal hipótesis fuera a explicar tales proposiciones generales, deberíamos, de acuerdo con la manera común de proceder de todas las ciencias, admitirla hasta que otra hipótesis mejor sea encontrada”.
Además, tal y como se ha explicado, el argumento de diseño de la información del ADN se adecua a los cánones empleados en las ciencias de la historia. El principio de uniformidad establece que “el presente es la clave del pasado”. En particular, el principio especifica que nuestro conocimiento de las relaciones actuales de causa y efecto debe gobernar nuestras valoraciones de la plausibilidad de las inferencias que hacemos acerca del pasado causal remoto. Sin embargo, es precisamente ese conocimiento de las relaciones de causa y efecto el que informa la inferencia del diseño inteligente. Ya que nosotros sabemos que los agentes inteligentes producen grandes cantidades de información, y ya que todos los procesos naturales conocidos no lo hacen, podemos inferir diseño como la mejor explicación del origen de la información en la célula.
La objeción de que la inferencia de diseño constituye un argumento nacido de la ignorancia se reduce en esencia a replantear el problema de la inducción. Sin embargo podría hacerse la misma objeción contra cualquier ley o explicación científica o contra cualquier inferencia histórica que tenga en cuenta el presente conocimiento, no en el futuro, de las leyes naturales y los poderes causales. Como han señalado Barrow y Tipler, criticar los argumentos de diseño, como hizo Hume, simplemente porque asumen la uniformidad y el carácter normativo de las leyes naturales realiza un profundo corte en “la base racional de cualquier forma de investigación científica”.
Nuestro conocimiento acerca de lo que puede y de lo que no puede producir grandes cantidades de información específica puede tener que ser revisado, pero lo mismo sucede con las leyes de la termodinámica. Las inferencias de diseño pueden demostrarse más adelante incorrectas, como sucede con otras inferencias que implican varias causas naturales. Tal posibilidad no detiene a los científicos a la hora de hacer generalizaciones acerca de poderes causales de varias entidades o de utilizar esas generalizaciones para identificar causas probables o muy plausibles en casos concretos. Las inferencias basadas en la experiencia presente y pasada constituye conocimiento, aunque provisional, pero no ignorancia. Aquellos que objetan contra tales inferencias objetan contra la ciencia, tanto como objetan contra una hipótesis de diseño particular de base científica.
Es evidente que algunos rechazan la hipótesis de diseño alegando que no alcanza la categoría de “científica”. Tales críticos afirman un principio fuera de toda evidencia conocido como naturalismo metodológico. El naturalismo metodológico afirma que, por definición, para que una hipótesis, teoría, o explicación sea considerada “científica”, tiene que invocar solo entidades naturalistas o materialistas. De acuerdo con tal definición, los críticos dicen que el diseño inteligente no es válido. Sin embargo, incluso si se da por buena esta definición, no se sigue que ciertas hipótesis no científicas, según las define el naturalismo metodológico, o metafísicas no puedan constituir una mejor explicación, más adecuada causalmente. Pero cualquiera que sea su clasificación, la hipótesis de diseño constituye una explicación mejor que sus rivales materialistas o naturalistas para el origen de la información biológica específica. Seguramente, la mera clasificación de un argumento como metafísico no lo refuta.
Para ser un buscador de la verdad, la cuestión que el investigador del origen de la vida debe plantearse no es “¿qué modelo materialista es el más adecuado?” sino más bien “¿qué provocó la aparición de la vida en la Tierra?”. Claramente, una posible respuesta a esta última cuestión sea esta: “la vida fue diseñada por un agente inteligente que existió antes del advenimiento de los humanos”. La apertura a la hipótesis del diseño parecería necesaria, por tanto, para cualquier biología histórica que busque la verdad, Una biología histórica comprometida a seguir la evidencia dondequiera que esta lleve, no excluirá hipótesis a priori por razones metafísicas. Este enfoque más abierto y más racionalsugeriría ahora la teoría del diseño inteligente como la mejor explicación o más adecuada causalmente para el origen de la información necesaria para construir el primer organismo vivo.
La evolucion propone la adptacion paulatina de una especie a su entorno, pero al mismo tiempo establece que solo sobreviven los mas fuertes y adaptados, lo que se conoce como seleccion, enonces cualquier organismo en fase de evolucion pereceria al no contar con las herrmientas necesarias para su supervivencia. PUNTO.
ResponderEliminar